Dự án nổi bật / 01
Ledger Automation Pipeline
Tự động hóa quy trình xử lý ledger kế toán bằng Python

Tóm tắt nhanh
Tổng quan dự án
Nội dung nghiên cứu
Vấn đề bắt đầu từ một buổi chiều làm kế toán thủ công
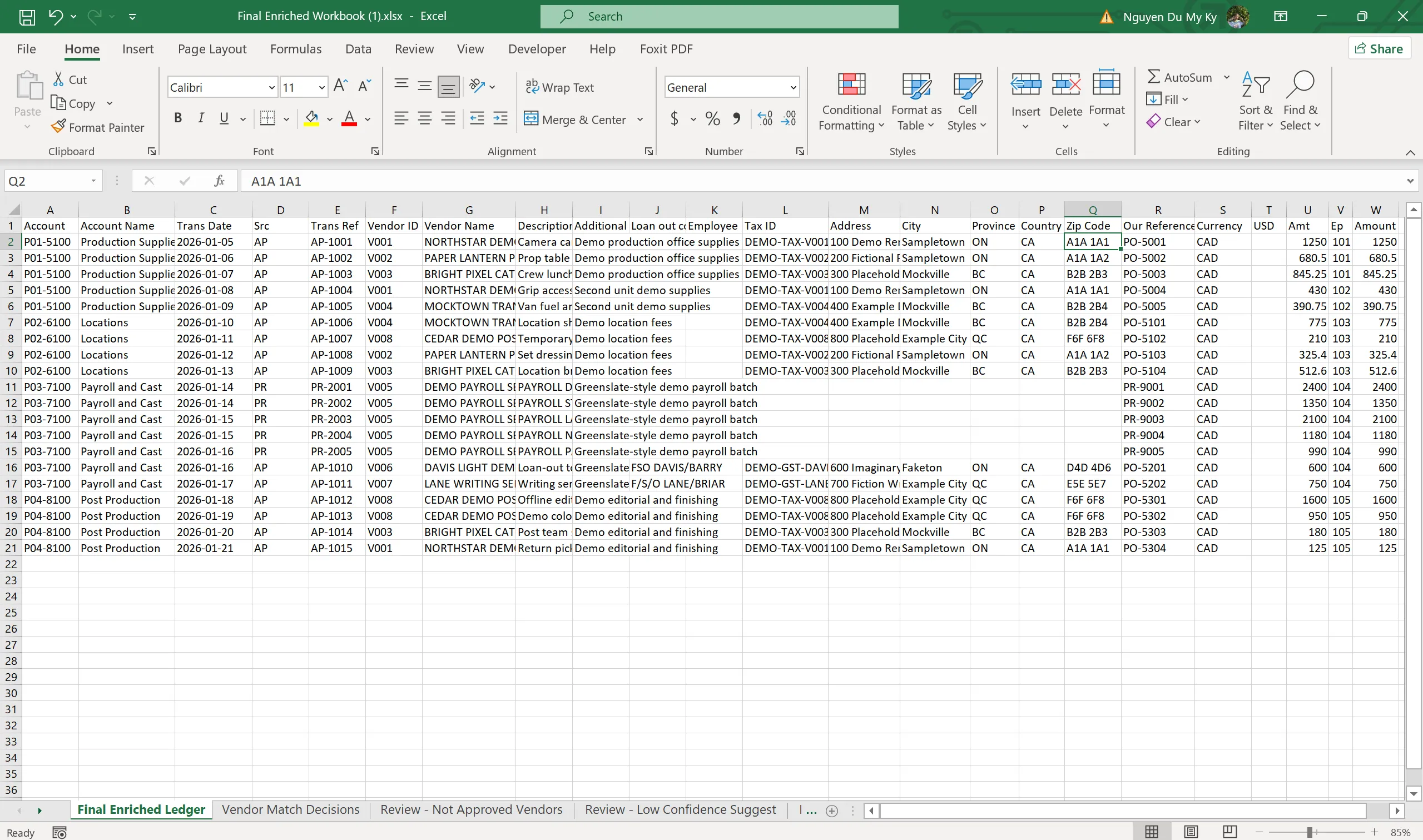
Không có đề bài, không có giảng viên giao việc. Project này bắt đầu từ một quan sát rất thật trong công việc: mỗi lần xuất ledger kế toán ra khỏi hệ thống, dữ liệu luôn ở dạng phân cấp (hierarchical) — rất khó để đọc trực tiếp, và trước khi dùng được cho bookkeeping, tax reporting hay audit review, luôn phải trải qua một loạt thao tác lặp đi lặp lại: làm sạch ledger, “làm phẳng” (flatten) dữ liệu, đối chiếu tên vendor, tra Tax ID, điền địa chỉ, nhận diện đúng nhân viên trong các dòng giao dịch payroll, rồi mới tổng hợp thành workbook cuối để review.
Nhìn quy trình đó, câu hỏi đặt ra không phải “làm sao làm nhanh hơn trên Excel”, mà là: liệu có thể biến toàn bộ pipeline này thành một quy trình tự động, nhưng vẫn giữ được bước kiểm duyệt của con người ở những chỗ rủi ro cao?
Vai trò: một mình từ đầu đến cuối
Đây là project cá nhân, nên toàn bộ vòng đời — từ xác định vấn đề, thiết kế pipeline, viết logic xử lý, đến xây giao diện và viết tài liệu — đều do một người đảm nhận:
- Thiết kế lại bài toán từ một workflow nghiệp vụ thật thành một kiến trúc phần mềm có cấu trúc
- Viết logic flatten ledger phân cấp thành transaction-level rows
- Xây dựng vendor matching bằng fuzzy matching (RapidFuzz) để gợi ý đối chiếu tên vendor với vendor master
- Thiết kế cơ chế nhận diện employee từ payroll description, có xử lý riêng cho loan-out corporation
- Thiết kế quy trình human-in-the-loop: hệ thống chỉ gợi ý, con người mới là người quyết định approve
- Xây dựng CLI và giao diện Streamlit để chạy pipeline
- Thiết kế file config dạng YAML để có thể tái sử dụng cho nhiều loại ledger khác nhau
- Chuẩn bị bộ dữ liệu giả (synthetic) để có thể public project lên GitHub mà không lộ dữ liệu công việc thật
Quá trình: tự động hóa, nhưng không tự động hóa quá mức
Phần khó nhất không phải là viết code match dữ liệu — mà là quyết định chỗ nào nên để máy tự quyết, chỗ nào phải để con người duyệt. Trong kế toán, một match sai có thể gây hậu quả thật, nên thiết kế ban đầu luôn đặt câu hỏi: nếu hệ thống không chắc, nó nên làm gì?
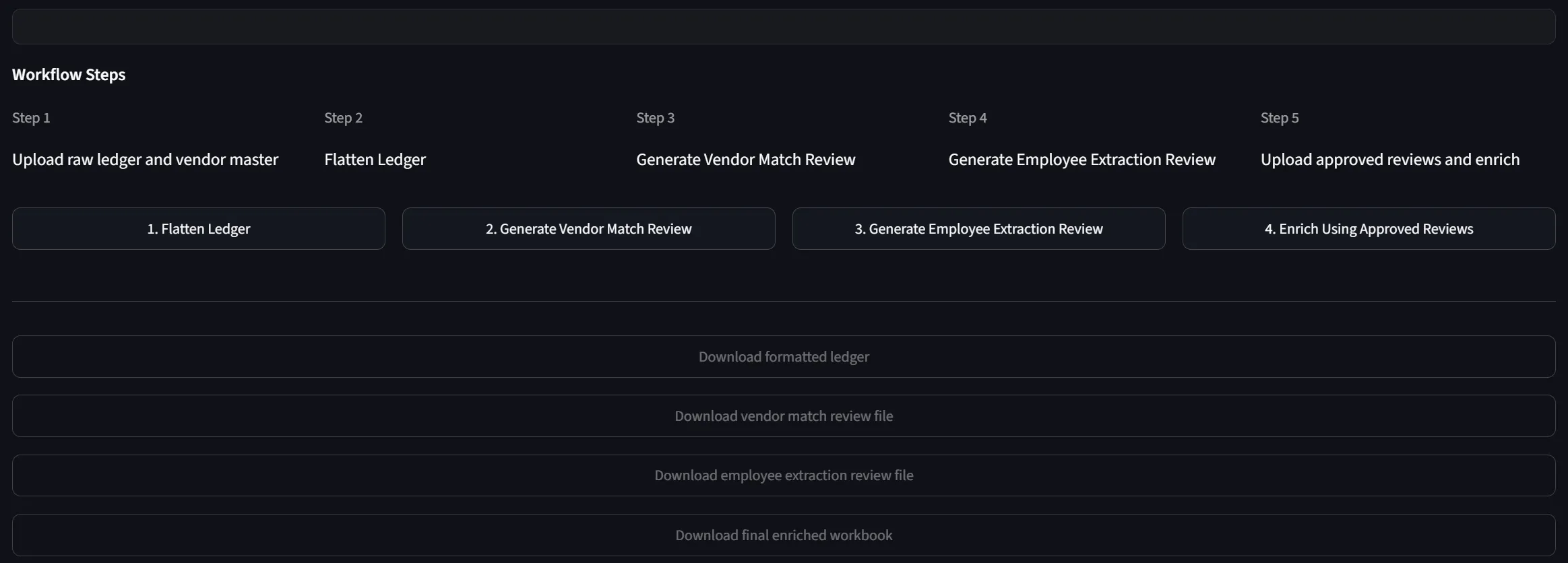
Câu trả lời được hiện thực hóa thành một pipeline có các bước rõ ràng:
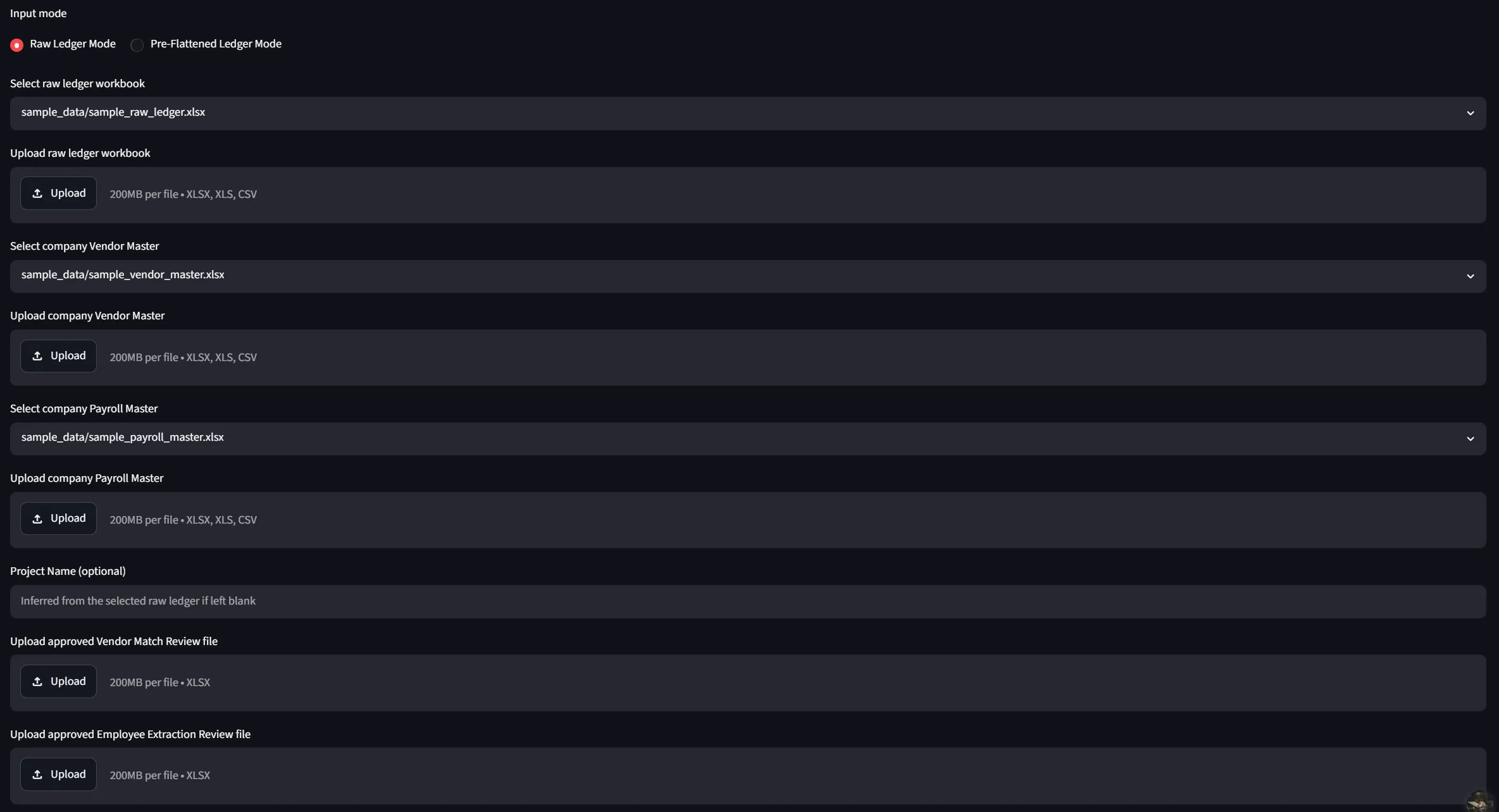
- Đọc ledger thô hoặc ledger đã được flatten sẵn
- Flatten ledger phân cấp thành các dòng giao dịch chuẩn (transaction-level rows) theo schema thống nhất
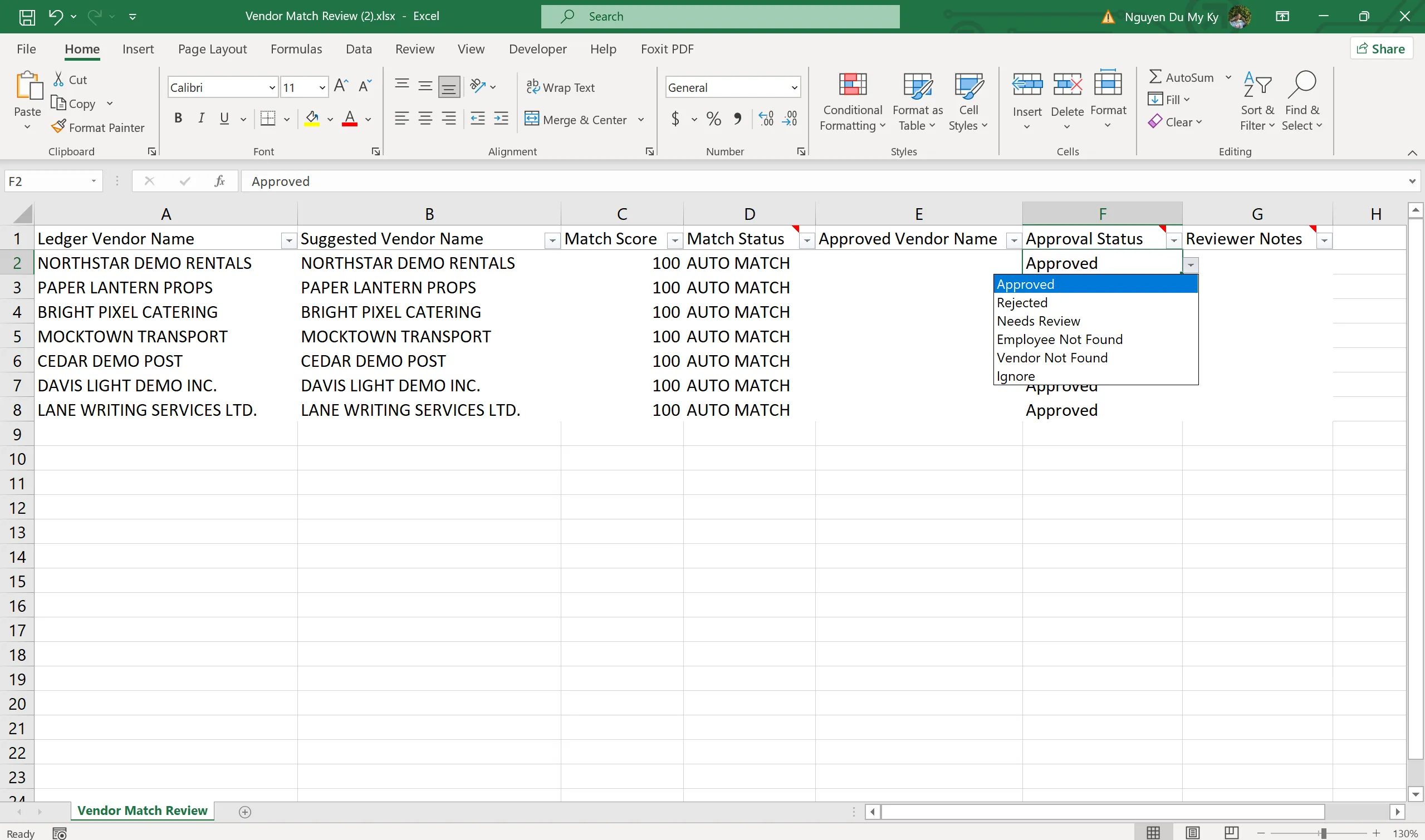
- Dùng fuzzy matching để gợi ý vendor tương ứng trong vendor master, sau đó xuất ra Vendor Match Review workbook để người dùng kiểm tra
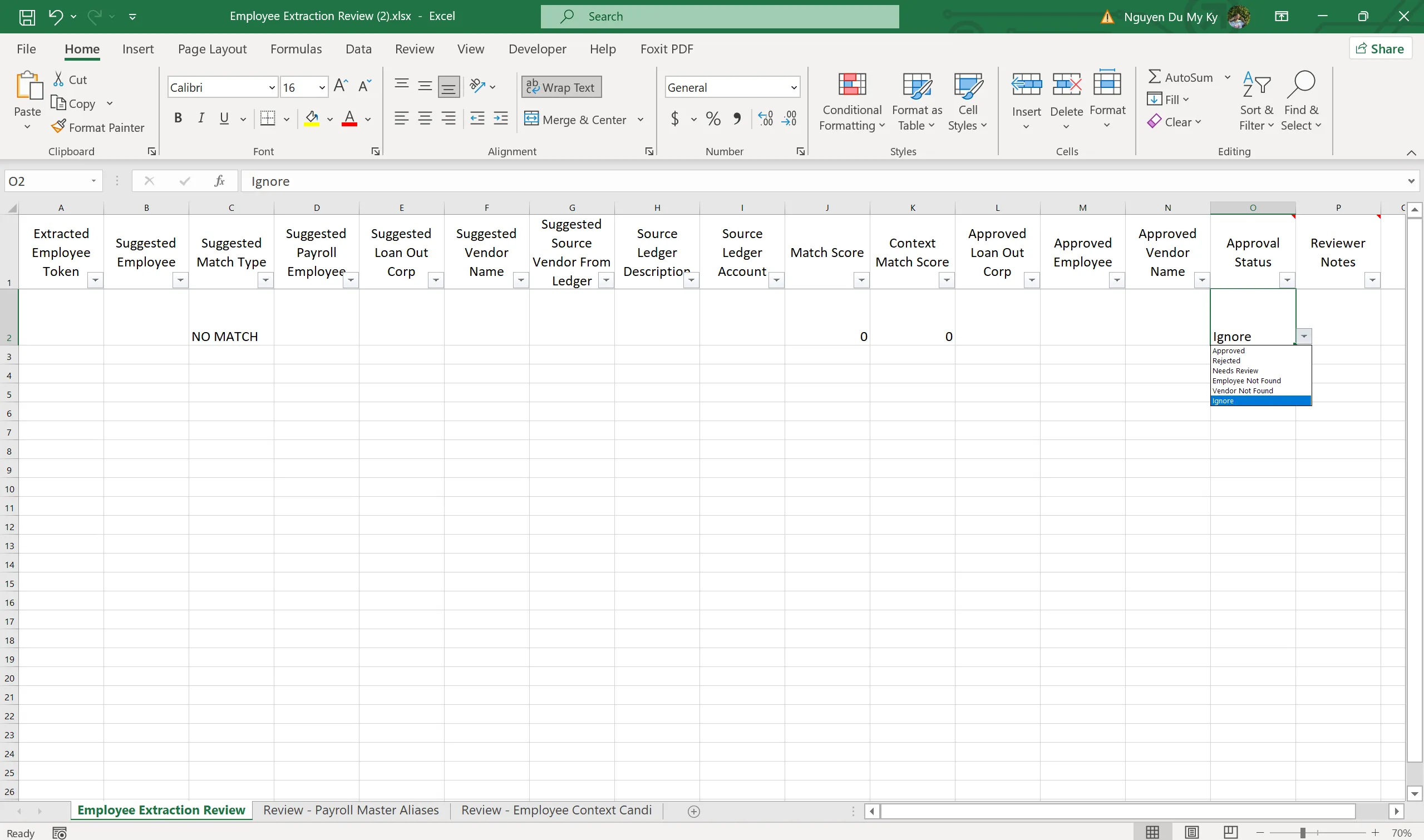
- Nhận diện các dòng thuộc payroll, trích xuất token nhận diện employee từ description, rồi match với payroll master hoặc loan-out alias — và cũng xuất ra Employee Extraction Review workbook
- Người review cập nhật Approval Status cho từng gợi ý
- Chỉ những gợi ý đã được approve mới được dùng để tạo ra Final Enriched Workbook — workbook cuối cùng có đầy đủ Tax ID, địa chỉ, employee và các sheet kiểm soát
- Toàn bộ quá trình được ghi lại qua run log và reconciliation summary để dễ truy vết khi cần audit lại
Cách thiết kế này giúp hệ thống không bao giờ “tự quyết” những trường hợp mơ hồ — nó chỉ rút ngắn phần lặp lại và đưa ra gợi ý có cơ sở, còn quyết định cuối vẫn thuộc về người làm kế toán.
Kết quả đạt được
- Pipeline xử lý ledger hoàn chỉnh từ đầu đến cuối, có cả CLI và giao diện Streamlit
- Hỗ trợ 2 kiểu input: ledger phân cấp thô và ledger đã được flatten sẵn
- Sinh ra đầy đủ Vendor Review, Employee Review và Final Enriched Workbook
- Có cơ chế approval rõ ràng — không enrich dữ liệu nếu chưa được con người duyệt
- Có run log, reconciliation summary và exception sheet phục vụ kiểm tra/audit
- Repository được tổ chức lại sạch sẽ, có demo public dùng dữ liệu giả an toàn để chia sẻ trên GitHub
Điều đáng giá nhất rút ra từ project này
Giá trị lớn nhất không nằm ở đoạn code matching, mà ở cách tiếp cận bài toán: không bắt đầu từ một bài tutorial, mà bắt đầu từ một điểm đau thật trong công việc. Project này cho thấy một câu chuyện rõ ràng — quan sát một quy trình lặp lại, dễ sai sót và phụ thuộc nhiều vào thao tác tay, rồi tự thiết kế lại nó thành một hệ thống có cấu trúc, có kiểm soát rủi ro và có thể tái sử dụng.
Đây cũng là lúc hiểu rõ hơn rằng automation tốt không phải là loại bỏ hoàn toàn con người khỏi quy trình, mà là giảm phần việc lặp lại, để con người dồn thời gian vào đúng những quyết định cần sự xét đoán.
Nếu làm lại
- Viết test tự động đầy đủ hơn cho các module flattening, vendor matching và employee extraction
- Thêm schema validation chi tiết hơn cho input workbook
- Tách rõ phần business logic ra một service layer riêng để dễ mở rộng
- Bổ sung authentication nếu triển khai trong môi trường nội bộ thật
- Làm thêm sơ đồ kiến trúc và video demo walkthrough để minh họa rõ hơn cho người xem portfolio
Lưu ý: toàn bộ dữ liệu công việc thật được giữ ở local. Bản public trên GitHub chỉ sử dụng dữ liệu giả (synthetic) được tạo riêng cho mục đích demo.
Nghiên cứu
Hình ảnh dự án
Bắt đầu trò chuyện
Bạn có một câu hỏi đáng để cùng khám phá?
Tôi sẵn sàng trao đổi về các vị trí dữ liệu, cơ hội hợp tác chỉn chu và câu chuyện phía sau nghiên cứu này.
Liên hệ